
Q1: We have coded speed reward function to reward agent when it moves in high speed, but it doesn’t seems working? Why is this happening? Also, if I clone a model, remove all the previous params and add the new ones that I wanna focused on, how would it goes? Will it work?
Answer: Cloning a model will inherit previous learning episodes. If you would like to start afresh, you can create a new model directly.
Q2: How to increase the speed of model. I tried various reward function to increase the speed of the model but it only get slightly above 1m/s at most. Do i need to create an aws account(not student portal) to customize my model and set the speed limit?
Answer: You can use the param ‘speed’ and SPEED_THRESHOLD to experiment with your reward function to increase the speed of the model.
Q3: May we enquire why is it the performance of the car getting worse after we switch multiple modes of training?
When I trained the car with “Follow the Centerline”, the time it achieved in leaderboard is 1:00. However after I trained it with “Stay within borders” and “Prevent Zig-zag”, it goes up to 1:02.
Answer: Performance of the model depends on your reward functionsand also the track. The current track that was chosen is relatively simple and linear hence a centerline focused reward function might perform relatively better.
When you submit the score, it’s an attempt at the track. So re-submitting the same model can yield different results too (suggest you submit at least 3 times to get a good score)
Q4: What is the ideal training time for each model? And if I have trained a model for 2 hours, and I clone it and train 30 minutes on top of it, will the model overfit? Or should I just created a new model and train it again?
Answer: To perform well in the virtual track, it needs at least 2 hours of training. To perform decent in the physical track, it’ll require between 4-8 hours of training at least. Beyond that, it’ll depend on your reward function and training results. In the pro console. you’ll be able to see the training graph which tells you if the training have been converged (i.e should stop).
When you clone a model, it will inherit the learning from previous training. Clone your model is more effective if you are tweaking your rewards function . If the reward function is a total overhaul, then it’s better to create a new one.
Q5: Why our model work so different on different account? One of the account are able to get a good time while the other account are lacking so much.
Why are there so many random accounts on the leaderboard?
Are we not supposed to change the hyperparameters at all?
Answer: All things being the same can still yield a different result at the leaderboard , especially when the models are not trained enough to be stable yet. It’s like asking a child to throw a ball in the basket, sometime he will score and sometime not. Ideal is to submit at least 3 times to get a good score.
Once your model is more stable given more training, the model timing will be more consistent.
For the student accounts, you can only choose hyperparameter “type” and cant adjust the actual which is only allowable in the pro accounts. That being said, the hyper parameters are generally quite optimised and focus should be on the reward function.
Q6: How can we set the optimal racing line ? Is the waypoints parameter a predefined set of coordinates that make up the optimal racing line or do we need to set the waypoints for the optimal racing line ourselves?
Answer: ‘waypoints’ refers to x,y coordinates of the track map. You can use combination of waypoints and closest_waypoints as calculations that can help you manouver your model with faster speed. Some samples – https://github.com/oscarYCL/deepracer-waypoints-workshop
Q7: What is the ‘step’ in the params? Steps of how many inputs I put into the reward function?
Answer: No, it refers to how many ‘inference steps” that your model have taken to complete the track. Meaning to say how many decisions it took.
Q8: Is that we only can modify on the rewards function right?
Answer: For Student League console, you will be only modifying rewards function. For successful finalist, you will have access to Deep Racer console which will have more advanced parameters to experiment such as the action space.
Q9: I am using the same model and did multiple enter race submission, but the results that I got every time, sometimes the difference is small, but sometimes the difference can be very huge (10seconds) difference, why is this happening and how to solve it?
Answer: All things being the same can still yield a different result at the leaderboard , especially when the models are not trained enough to be stable yet. It’s like asking a child to throw a ball in the basket, sometime he will score and sometime not.
When you submit the score, it’s an attempt at the track. So re-submitting the same model can yield different results too (suggest you submit at least 3 times to get a good score)
Once your model is more stable given more training, the model timing will be more consistent.
Q10: How can I have my model maintain its speed constantly throughout the race?
Answer: You can experiment with the params for ‘speed’ in your rewards function to manipulate your speed throughout the race. An example is to reward it for maintaining a certain speed.
Q11: Our team train 2 models, two models using the same code, the first one train like 2 hours, second train 4 hours, in my logic, train more hour the results will be more efficient right, but why the first model run about 54s however second model run 56s. This quite confuse me.
Answer: All things being the same can still yield a different result at the leaderboard , especially when the models are not trained enough to be stable yet. It’s like asking a child to throw a ball in the basket, sometime he will score and sometime not.
When you submit the score, it’s an attempt at the track. So re-submitting the same model can yield different results too (suggest you submit at least 3 times to get a good score)
Once your model is more stable given more training, the model timing will be more consistent.
Q12: How do i increase the speed of my model?
Answer:You can use the speed params to increase your speed by giving more rewards if the speed increases.
Q13: How do I implement the waypoint map to the waypoint reward function?
Answer: You can use combination of calculations of waypoint and closest_waypoint params as calculations to help you manouver your model.Some samples – https://github.com/oscarYCL/deepracer-waypoints-workshop
Q14: What is the average optimal training time (like a rough estimate of how long an effective training time should be)?
Answer: There isn’t one answer to this question. The factors that can influence the training time include:
– size of the action space and what actions it contains
– whether they can give a complete lap and whether there aren’t too many actions in there
minimum/maximum speed in the training
– if it’s too high, the car can fail to get around the turns
complexity of the reward function
– too many elements and it will take longer to find the right behaviour (and more difficult), not enough and the car may learn to perform suboptimal actions
strategy in the reward function
– are you rewarding behaviour or state, or maybe something else?
correctness of the reward function
– is your reward actually rewarding completion of a lap?
Typically speaking, a simple reward function such as following the center line will take 2 hours to perform decent in virtual track. And at 4-8 hours to perform well at physical track.
Q15: How an agent that have camera or sensor know that is center line and its wheels is going off track through a block of code?
Answer: Through params such as [‘distance_from_center’], [‘all_wheels_on_track’
You can view the list of params from the link https://docs.aws.amazon.com/deepracer/latest/developerguide/deepracer-reward-function-input.html
Q16: Will the training time get refreshed for the top 10 finalist?
Answer: Yes, Finalist will have everything reset as your will have a new track and new console.
Q17: Hi, it says that the parameter “progress” is not recognised, but in the briefing slides list of parameters we can use, “progress” was available.
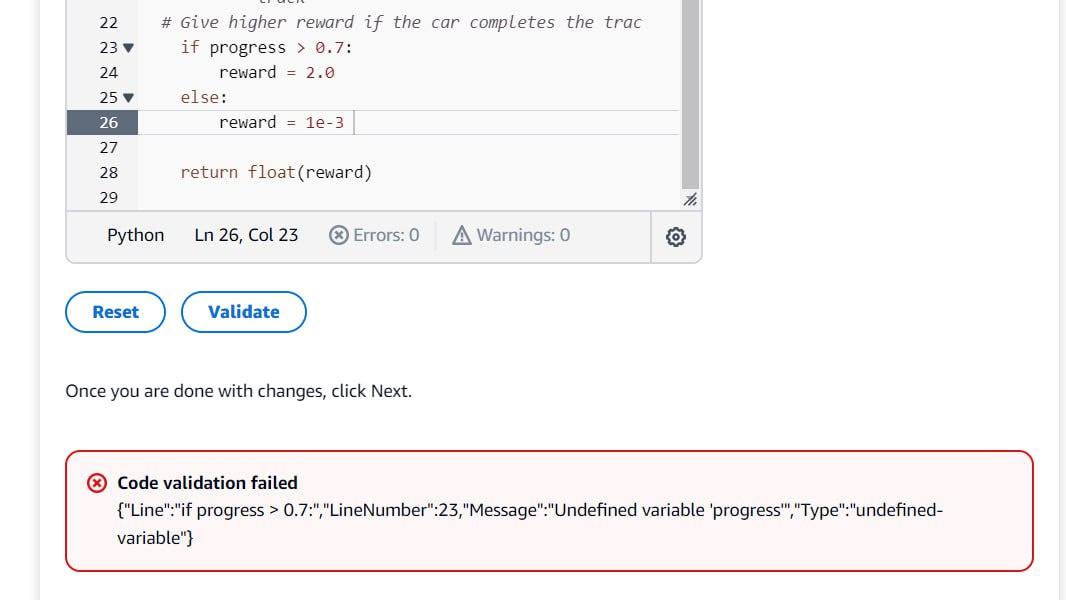
Answer: ‘progress’ is a valid parameter and should work well.
You can refer to https://docs.aws.amazon.com/deepracer/latest/developerguide/deepracer-reward-function-input.htmlfor the list of parameters